I was at a datathon weekend which was organized by a collaboration between Aarhus University, MIT, and Google Cloud. The team I was on[1] looked into interpreting Chest X-ray pathology classifications.
To fit the scope to the timeline of the datathon, we restricted our analysis to three pathologies visible on x-ray scans of the chest area.
How SHAP works
SHAP (SHapley Additive exPlanations) is a model agnostic feature attribution algorithm.
Broadly, SHAP works by slightly tweaking the inputs, and then measuring the corresponding change in the output. If a the output is particularly sensitive to an input feature (i.e. a pixel), then we attribute that feature a higher significance.[2]
Notably, ideally, this would give us locality to classification labels without explicitly having to label and train the model on labeled segmentation data which can often be prohibitably expensive.
Results
We found that SHAP reported that the model has learned to use the text-snippet in the upper-left corner indicating if the patient is sitting or lying down.
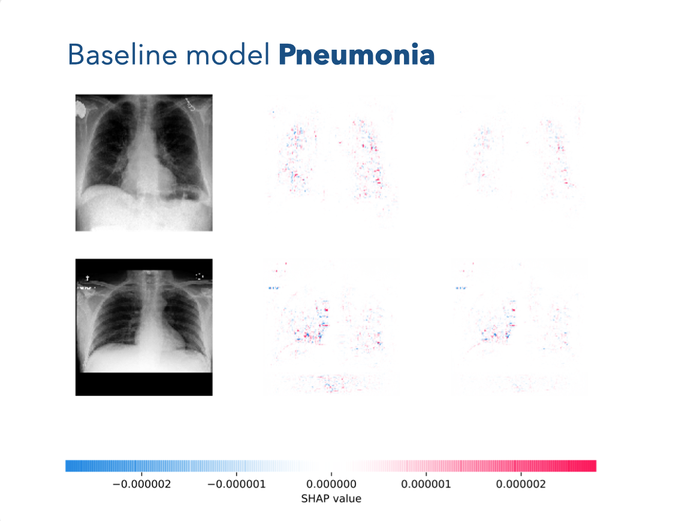
This is problematic for many reasons. Not only does it encode the biases of doctors deciding if the patient is fit to sit up to have the X-ray scan, but it also isn't information which should be used to make the diagnosis. In the worst case, it can lead to very confident, but wrong diagnoses which can cost someone their lives.
We tried fine-tuning the model to just the pathologies we were interested in to see if further training could help it pick up some of the smaller nuances.
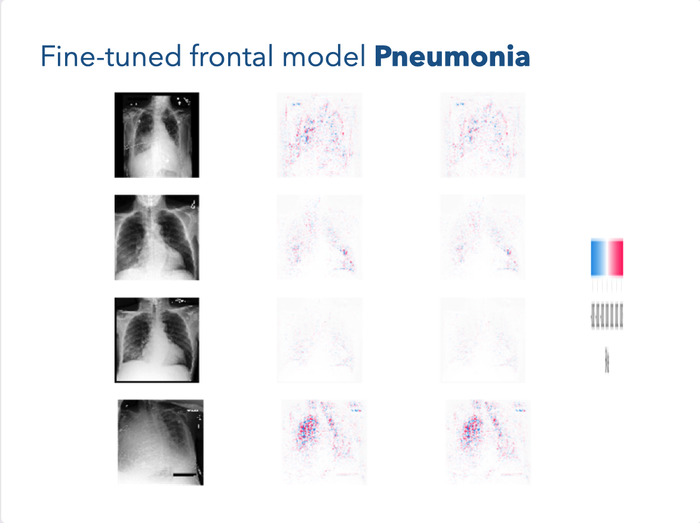
We see that even with finetuning, it still appears to be sensitive to the overlayed text, but it has also gotten increased sensitivity to the chest and seems to pick up and locate instances of pneumonia.
Conclusion
We found that SHAP is a useful tool to get the locality of global information without explicitly training for it. It is therefore a cost effective tool to increase confidence and Interpretability of the model's correctness. Moreover, we found that it's valuable as a diagnostic tool to find instances where the model classifies the wrong thing even if it has a good classification accuracy. Our analysis also shows the importance of interpretability of deep learning models in high stakes applications, and how they can be sneaky about what they are learning.
Footnotes
- Mathis Rasmussen, Davide Placido, Cristina Leal Rodriguez, and Gianluca Mazzoni were also on the team.
- For a more thorough explanation see A Unified Approach to Interpreting Model Predictions.