Today I learned: Extremely quantized networks (down to 1.53 Bits) are still capable and useful, and efficiency seems to increase with size of networks. This enables specialised hardware for extremely efficient inferences.
I have noticed the trend of quantizing neural networks has been unreasonably effective at retaining accuracy while benefitting from the memory improvements, and opening up the possibility of designing special hardware that natively operate with the lower bit levels.
Ma 2024 takes quantization to the extreme clipping the weight values to be in the set $\{-1,0,1\}$ leading to large improvements in memory footprint of around $30$-$40\%$ of the original (with larger models having higher relative improvements) as well as significant improvements in latency and throughput, and they do all this while retaining the accuracy.
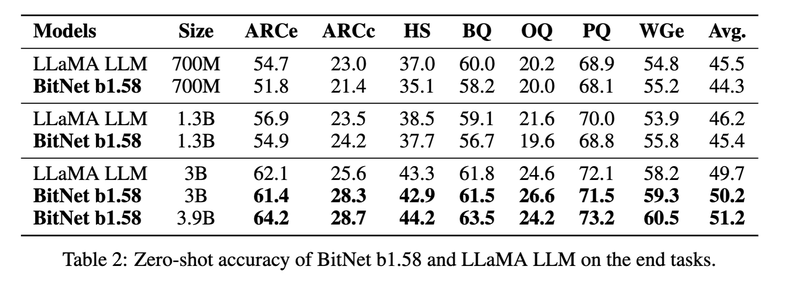
If we combine this with the effectiveness of knowledge distillation, it would suggest that large models are largely inefficient.
I find this exciting for the prospect of running well performing models on edge devices which is desirable for numerous reasons including better UX and better privacy.