A story that periodically makes the rounds on the internet is about a time in the 1980s when the US department of defense wanted to teach computers to automatically detect camouflaged enemy tanks.
The US department of defense, in their never ending wisdom, wanted to make their tanks less prone to be shot. A reasonable proposition. After all, getting shot by a tree would presumably be even worse than Mondays.
This was an especially productive day, for not only did they make the revolutionary insight that it helps not getting shot on the battlefield, but they also wanted to use this new computer technology thing to achieve this.
They decided to train a neural network to spot camouflaged enemy tanks. Since neural networks need a lot of data, they went out and gathered 100 images some of camouflaged tanks, and another 100 images without any tanks in them.[^1]
[^1]: It was simpler times back then.
It all went well, and after they had trained the network, they found it to be doing a nearly perfect job at segmenting the trees that were really tanks from those which were just trees.
They were quick to send the model to the pentagon for review, perhaps expecting a pay raise for their fast delivery.
Upon seeing the remarkable results, the engineers at the pentagon were skeptical of the true effectiveness, so they went out and gathered a new batch of images for testing.
Confirming their suspicion, they found that when using the new data, the network was no better at classifying tanks than a monkey guessing randomly.
If you're an experienced machine learner, or just want a challenge, you can try and guess what might be the reason for the difference in accuracy.
Ready?
Okay.
This is a case of high variance that causes the model to overfit the training data. Therefore, when confronted with the new data, the model fails to perform as well as it did on the initial data.
We might further hypothesis that it will be difficult to combat using regularization due to the extraordinarily small amount of training data (only 100 images).
It turns out that the neural network hadn't learned to recognize camouflaged tanks, but instead had learned to recognize whether it's cloudy or not. This was possible because it just happened that the images containing the camouflaged tank were also taken on a cloudy day, while the images not featuring a tank were not.
An obvious question to ask is why the neural network learned to detect if it's cloudy, when they were training it to recognize tanks?
Even though this might seems weird, it's actually a rather significant insight.
Artificial neural networks such as those you might train to recognize a tank fundamentally don't understand the concept of a tank; to it, it's all just numbers. So to train a neural network, you have to show it a lot of data, and hope that it will figure out what we mean by there being a camouflaged tank.
The problem of neural networks overfitting on the data, and not learning what we expect them to was not just a problem present in the 80ies when computers where slow, but continues to be a problem today.
In fact it's an area in which there's a lot of research going on even today. For example, Google recently published a paper on adverserial patches where they exploit a type of neural network which is really good at recognizing what's in an image, like superhuman good, and make it believe something that's clearly a picture of, say, a banana, is actually a picture of a toaster.
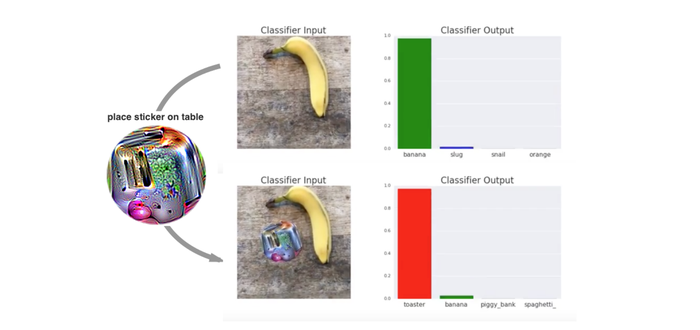
On the image above we see that the patch in form of a sticker with a mysterious abstract picture printed on it can trick the model into thinking what's clearly a banana is actually a toaster.
This is possible because neural networks don't actually understand the concept of a banana, but instead finds its own representation for a banana which we hope will match our intuition at least in everything we measure it in. And it turns out that the network's understanding of banana doesn't match our understanding of a banana.
We can then trick the network's internal understanding or representation of a banana, by using the representation of another object to trick the network. Here, the representation is printed on a sticker, but there are also variations where you add a noise layer which isn't noticeable to humans .
In fact, it's even possible to fool a neural network by changing just a single pixel if you know which one and how to change it.
Now, this, like most things in the essay, is a simplification. For example, you actually use two networks; one to figure out what's in the image, and another to try and cheat the first network - an adversarial network. However, the general idea is there.
Being able to reliably cheat a neural network in a way that's difficult to detect by humans pose a significant security risk. For example, continuing the sticker example, an attacker may place these stickers on streetsigns which could lead self-driving cars to operate under a false understanding of their environment.
While the story gained most of its popularity after Yudkowsky, an American AI researcher, used it in the manuscript "Artificial Intelligence as a Positive and Negative Factor in Global Risk", the original source is still disputed which makes it unclear how much of the story is true, and how much is just an urban legend.